AI đang hỗ trợ con người xử lý nhiều công việc phức tạp, nhưng lại gặp khó khăn với kiến thức Toán, như cho rằng 9,11 lớn hơn 9,9.
TheoSCMP, câu chuyện bắt đầu từ chương trình truyền hình thực tếSinger 2024do Đài truyền hình Hồ Nam sản xuất và phát sóng cuối tuần trước ở Trung Quốc. Thí sinh Sun Nan nhận được 13,8% lượt bình chọn trực tuyến, vượt qua thí sinh người Mỹ Chanté Moore với 13,11% phiếu bầu.
Tuy nhiên, nhiều người dùng Trung Quốc không hài lòng và chế giễu trên mạng xã hội rằng "11 phải lớn hơn 8", ý nói thí sinh Moore biểu diễn tốt hơn nhưng lại thua.
Một số sau đó thử hỏi các mô hình AI phổ biến ở nước này và nhận được kết quả "bất ngờ".
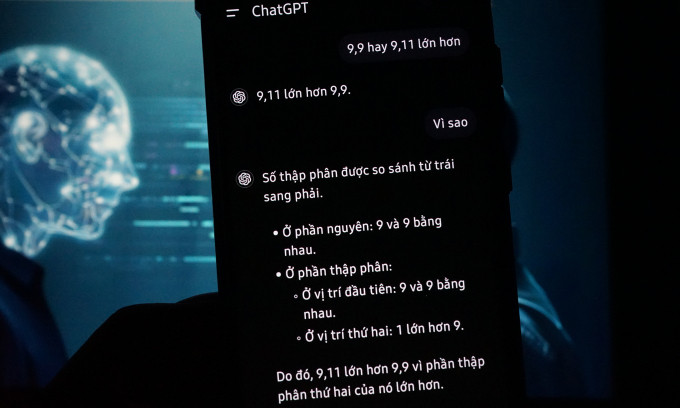
ChatGPT trả lời sai với câu hỏi: "9,9 hay 9,11 lớn hơn?". Ảnh: Bảo Lâm
Cụ thể, khi hỏi 9,9 hay 9,11 lớn hơn, hai chatbot phổ biến là Kimi của Moonshot AI và Baixiaoying của Baichuan đều đưa ra câu trả lời sai rằng 9,11 lớn hơn.
Cả hai đã sửa thuật toán sau khi người dùng phàn nàn, đồng thời xin lỗi và đưa ra nguyên nhân nằm ở sự không chính xác của "phương pháp tiếp cận chuỗi suy nghĩ", trong đó AI được hướng dẫn từng bước đối với một vấn đề. Ví dụ, AI tách con số sau dấu phẩy, từ đó so sánh 11 với 9 và khẳng định 11 lớn hơn, nên 9,11 cũng lớn hơn.
Một số AI phải cần đến công đoạn phức tạp hơn. Chẳng hạn, Qwen LLM của Alibaba sử dụng Python Code Interpreter để tính toán câu trả lời, trong khi Ernie Bot của Baidu thực hiện diễn giải 6 bước mới trả lời đúng.
Trong khi đó, một số AI khác lại trả lời chính xác khá nhanh. Doubao LLM của ByteDance phản hồi bằng ví dụ: "Nếu bạn có 9,90 đô la Mỹ và 9,11 đô la Mỹ, rõ ràng 9,90 nhiều hơn".
Người dùng tại Việt Nam cũng thử với các mô hình AI phổ biến. ChatGPT chạy GPT-3.5 và GPT4-o đều phản hồi sai rằng 9,9 bé hơn. Claude Claude 3.5 Sonnet và Mistral AI cũng trả lời không chính xác, còn Gemini của Google đưa ra đáp án đúng.
Theo Wu Yiquan, nhà nghiên cứu khoa học máy tính tại Đại học Chiết Giang ở Hàng Châu, việcAIkhông giỏi toán rất phổ biến. Các mô hình ngôn ngữ lớn (LLM) đứng sau không sở hữu khả năng toán học, bởi chúng dự đoán câu trả lời dựa trên dữ liệu đào tạo.
"Một số LLM hoạt động tốt trong bài kiểm tra toán có thể là do 'nhiễm dữ liệu', nghĩa là thuật toán đã ghi nhớ câu trả lời vì các câu hỏi tương tự đã có trong dữ liệu đào tạo của nó", Yiquan giải thích. "Thế giới AI được mã hóa, do đó số, từ, dấu câu và khoảng trắng đều được xử lý như nhau. Bất kỳ thay đổi nào trong lời nhắc đều có thể ảnh hưởng đáng kể đến kết quả".
Trước đó, trên X, nhà nghiên cứu Bill Yuchen Lin của Allen Institute và kỹ sư Riley Goodside của Scale AI cũng đã nêu những thiếu sót cơ bản về toán học của LLM. Cả hai cho biết LLM "có khả năng toán học kém" khi kiểm tra và so sánh số, do dữ liệu được đào tạo không phục vụ riêng cho việc tính toán. Mỗi mô hình đang "học" dữ liệu dàn trải ở đa dạng lĩnh vực và có xu hướng vĩ mô, do đó có thể sai các kiến thức cơ bản.
Theo hai chuyên gia này, người dùng không nên tin tưởng hoàn toàn vào các mô hình AI. Thực tế, chúng nhiều lần bị phát hiện trả lời sai hoặc gặp tình trạng "ảo giác", tức bịa ra câu trả lời sao cho nghe có vẻ thuyết phục nhất.










Ý kiến ()