Tất cả chuyên mục
Chủ Nhật, 06/07/2025 08:23 (GMT +7)
Công cụ AI mới của Microsoft chỉ cần nghe 3 giây giọng nói của bạn để bắt chước bạn
Thứ 5, 12/01/2023 | 07:39:09 [GMT +7] A A
VALL-E có thể bảo tồn giai điệu cảm xúc của người nói ban đầu, thậm chí mô phỏng môi trường âm thanh của họ.
Bất chấp những tiến bộ trong việc tạo video AI đã đạt được như thế nào, nó vẫn yêu cầu khá nhiều tài liệu nguồn, chẳng hạn như ảnh chụp trực diện từ nhiều góc độ khác nhau hoặc cảnh quay video để tạo ra một phiên bản deepfake thuyết phục về chân dung của một người. Khi nói đến việc giả giọng nói, đó lại là một câu chuyện khác, vì các nhà nghiên cứu của Microsoft gần đây đã tiết lộ một công cụ AI mới có thể mô phỏng giọng nói của ai đó chỉ bằng cách sử dụng một đoạn mẫu họ nói trong 3 giây.
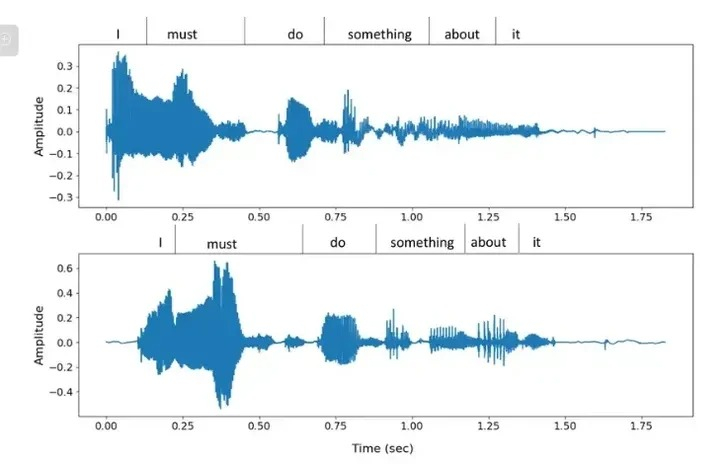
Công cụ mới, một “mô hình ngôn ngữ codec thần kinh” có tên là VALL-E, được xây dựng trên công nghệ nén âm thanh EnCodec của Meta, được tiết lộ vào cuối năm ngoái, sử dụng AI để nén âm thanh chất lượng tốt hơn CD thành tốc độ dữ liệu nhỏ hơn 10 lần so với tốc độ truyền dữ liệu file MP3 mà không làm giảm chất lượng đáng kể. Meta đã hình dung EnCodec là một cách để cải thiện chất lượng cuộc gọi điện thoại ở những khu vực có vùng phủ sóng di động thưa thớt hoặc là một cách để giảm nhu cầu băng thông cho các dịch vụ phát nhạc trực tuyến, nhưng Microsoft đang tận dụng công nghệ này như một cách để biến quá trình tổng hợp văn bản thành giọng nói nghe hay hơn thực tế dựa trên một mẫu nguồn rất hạn chế.
Các hệ thống chuyển văn bản thành giọng nói hiện tại có thể tạo ra giọng nói rất chân thực, đó là lý do tại sao các trợ lý thông minh có âm thanh rất chân thực mặc dù các phản hồi bằng lời nói được tạo ra một cách nhanh chóng. Nhưng chúng yêu cầu dữ liệu đào tạo chất lượng cao và rất rõ ràng, dữ liệu này thường được ghi lại trong phòng thu âm với thiết bị chuyên nghiệp. Cách tiếp cận của Microsoft giúp VALL-E có khả năng mô phỏng giọng nói của hầu hết mọi người mà không cần họ phải dành hàng tuần trong phòng thu. Thay vào đó, công cụ này được đào tạo bằng cách sử dụng bộ dữ liệu Libri-light của Meta, chứa 60.000 giờ bài phát biểu bằng tiếng Anh được ghi âm từ hơn 7.000 người nói duy nhất, “được trích xuất và xử lý từ sách nói LibriVox”, tất cả đều thuộc phạm vi công cộng.
Microsoft đã chia sẻ một bộ sưu tập phong phú các mẫu do VALL-E tạo ra để bạn có thể tự mình nghe thấy khả năng mô phỏng giọng nói có khả năng như thế nào, nhưng kết quả hiện tại là một túi hỗn hợp. Đôi khi, công cụ này gặp sự cố khi tạo lại các dấu, kể cả những dấu tinh tế từ các mẫu nguồn mà người nói phát ra âm thanh Ailen và khả năng thay đổi cảm xúc của một cụm từ nhất định đôi khi gây cười. Nhưng thông thường, các mẫu do VALL-E tạo ra có âm thanh tự nhiên, ấm áp và hầu như không thể phân biệt được với loa gốc trong ba clip nguồn thứ hai.
Ở dạng hiện tại, được đào tạo trên Libri-light, VALL-E bị giới hạn trong việc mô phỏng giọng nói bằng tiếng Anh và mặc dù hiệu suất vẫn chưa hoàn hảo, nhưng chắc chắn nó sẽ cải thiện khi bộ dữ liệu mẫu được mở rộng hơn nữa. Tuy nhiên, việc cải thiện VALL-E sẽ tùy thuộc vào các nhà nghiên cứu của Microsoft vì nhóm không phát hành mã nguồn của công cụ. Trong một bài báo nghiên cứu được phát hành gần đây trình bày chi tiết về sự phát triển của VALL-E, những người tạo ra nó hoàn toàn hiểu những rủi ro mà nó gây ra:
“ Vì VALL-E có thể tổng hợp giọng nói để duy trì danh tính của người nói nên nó có thể tiềm ẩn rủi ro khi sử dụng sai, chẳng hạn như nhận dạng giọng nói giả mạo hoặc mạo danh một người nói cụ thể. Để giảm thiểu những rủi ro như vậy, có thể xây dựng mô hình phát hiện để phân biệt xem clip âm thanh có được tổng hợp bởi VALL-E hay không. Chúng tôi cũng sẽ áp dụng các Nguyên tắc Trí tuệ nhân tạo của Microsoft vào thực tiễn khi tiếp tục phát triển các mô hình”, theo Microsoft.
Theo Vnreview






Liên kết website










Ý kiến ()